A block design is where we have sets of similar trials organised into blocks rather than having trials interleaved.
a block of faces to recognise or a block of houses
a faces oriented correctly and faces inverted
a block of Stroop task in English and a block in French
The biggest error that people make with this is to create a Routine (and a loop) for each block of trials:

Then they ask on the forum, “How do I shuffle the blocks on my Flow?”
That is the wrong way to think about it.
Instead of a Routine for each block, create a Routine for all your trials and make it behave differently across the blocks:

Then you can set the conditions files in your blocks loop to control the block-level changes.
The outer “blocks” loop then takes a (meta) “conditions” file that specifies which of the conditions files will be loaded in each block.
Imagine we want to extend our Posner task to include a block where invalid trials occur on 80% or trials.
We need to create a total of 3 conditions files:
conditions20.xlsx
conditions80.xlsx
blocks.xlsx
blocks.xlsx:
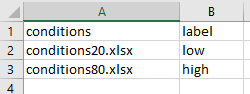
The label variable isn’t technically needed but it could be used to tell people what block they are about to enter. The point is that you can still use other variables here, defined at the block level of the program.
Now we need to set up the variables inside our experiment:
the inner (trials) loop will have a conditions file = $conditions which is defined in the blocks.xlsx file
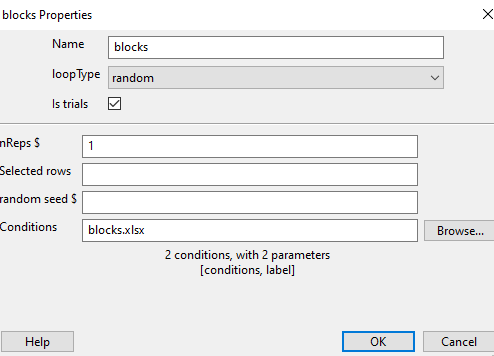
the outer (blocks) loop will have conditions file = blocks.xlsx
Setting loopType to random means that currently we have a randomised block design. The condition files listed in blocks.xlsx will be presented in a random order.
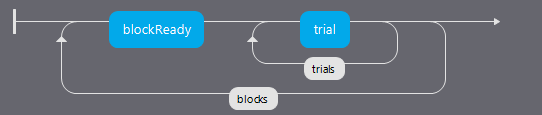
We could also add a Routine called blockReady like an instructions Routine with:
a text object that says:
$"This block will have a %s probability of invalid cues \n \n Press a key when ready" %(label)
a mouse object to advance to the next trial
You’ve sorted out block designs in a relatively neat fashion.
Just keep clear what differs from one block to the next (for a conditions file) and what stays the same (for the Routine definition).
Counterbalancing your blocks is really just an extension of the blocking scenario, except that you set the blocks to operate in a particular order rather than leaving PsychoPy to randomise them.
PsychoPy doesn’t handle the ordering for you - you need to decide how to create the orders and how to assign participants.
Now, rather than a single file to specify the blocks you need one for each order that you want the blocks to appear in (and then set the blocks loop to be sequential rather than random to preserve the order you set)
For instance, the Posner task you might have groupA with alternating invalid cue probability, beginning with high prob, and the groupB participants might have the same but starting with low prob.
Easiest way is by hand at the start of the run for the participant. The steps are:
In Experiment Settings add a field for group (which will be A, B, C… for however many orders you need to create)
For the block loop use that value by calling expInfo[‘group’] using one of the alternatives below:
$”block” + expInfo[‘group’] + “.xlsx”
$”block{}.xlsx”.format( expInfo[‘group’] )
You can now create trials and blocks in any order, fixed or random.
You’re in complete control (but you need to understand what orders you want!)
For online use we could also use this handy tool for generating sequential participant IDs
You don’t need to know how to code in order to make an experiment in PsychoPy. But, as we have seen, understanding a few simple concepts can really help in making tasks more flexible (e.g. if statements) and PsychoPy allows us to inadvertently learn some coding principles.
Let’s practice using Code Components